Sparsity is a fundamental principle that resonates through nature and engineering, where ***complexity can be reduced without compromising accuracy***
Our brain is teeming with neurons, but not every neuron is interconnected with another. The principle of sparsity in neural connections prevents overstimulation and reduces energy consumption, through a system of sparse connections that selectively activate during specific tasks, switching off less crucial connections.
Eg. Harnessed by the Google PageRank algorithm in the selective use of sparse connections, paying attention to the most critical links b/w individual webpages and ignoring the rest in a sea of info.
#### Why Sparsity
We know that [overparameterised neural networks](https://www.pnas.org/doi/10.1073/pnas.1903070116) generalize well. We've witnessed the rise and success of large models (e.g., [AlphaFold](https://www.nature.com/articles/s41586-021-03819-2), [GPT-3](https://arxiv.org/abs/2005.14165), [DALL-E](https://arxiv.org/abs/2102.12092), [DLRM](https://arxiv.org/abs/1906.00091)), but they are expensive to train and becoming economically, technically, and environmentally unsustainable ([Thompson et al. 2020](https://arxiv.org/abs/2007.05558)). For example, a single training run of GPT-3 takes a month on 1,024 A100 GPUs and costs $12M.
An ideal model should use less computation and memory while retaining the generalization benefits of large models.
Let's sparsify these models -- sparsify matrix multiplications, fundamental building blocks behind neural networks.
Sparsity is not new! It has a **long** history in machine learning ([Lecun et al. 1990](https://papers.nips.cc/paper/1989/hash/6c9882bbac1c7093bd25041881277658-Abstract.html)) and has driven fundamental progress in other fields such as statistics ([Tibshirani et al. 1996](https://www.jstor.org/stable/2346178)), neuroscience ([Foldiak et al. 2003](https://research-repository.st-andrews.ac.uk/handle/10023/2994)), and signal processing ([Candes et al. 2005](https://arxiv.org/abs/math/0503066)). What is new is that in the modern overparameterized regime, sparsity is no longer used to regularize models -- sparse models should behave as close as possible to a dense model, only smaller and **faster**.
#### The Opportunity
Sparse [[Large Language Model - LLMs]] that **maintain the benefits of overparameterization** while reducing computational and memory demands, could be the future.
Reducing these demands not only cuts costs but also speeds up model training, eases deployment, democratizes machine learning access, and lessens environmental impact.
---
#### The Challenges
- **Choice of Sparse Parameterization**: Many existing methods, e.g., pruning ([Lee et al. 2018](https://openreview.net/forum?id=B1VZqjAcYX), [Evci et al. 2020](https://openreview.net/forum?id=ryg7vA4tPB)), lottery tickets ([Frankle et al. 2018](https://openreview.net/forum?id=rJl-b3RcF7)), hashing ([Chen et al. 2019](https://proceedings.mlsys.org/paper/2020/hash/65b9eea6e1cc6bb9f0cd2a47751a186f-Abstract.html), [Kitaev et al. 2020](https://openreview.net/forum?id=rkgNKkHtvB)) maintain **dynamic** sparsity masks. However, the overhead of evolving the sparsity mask often slows down (instead of speeds up!) training.
- **Hardware Suitability**: Most existing methods adopt unstructured sparsity, which may be efficient in theory, but not on hardware such as GPUs (highly optimized for dense computation). An unstructured sparse model with 1% nonzero weights can be as slow as a dense model ([Hooker et al. 2020](https://arxiv.org/abs/2009.06489)).
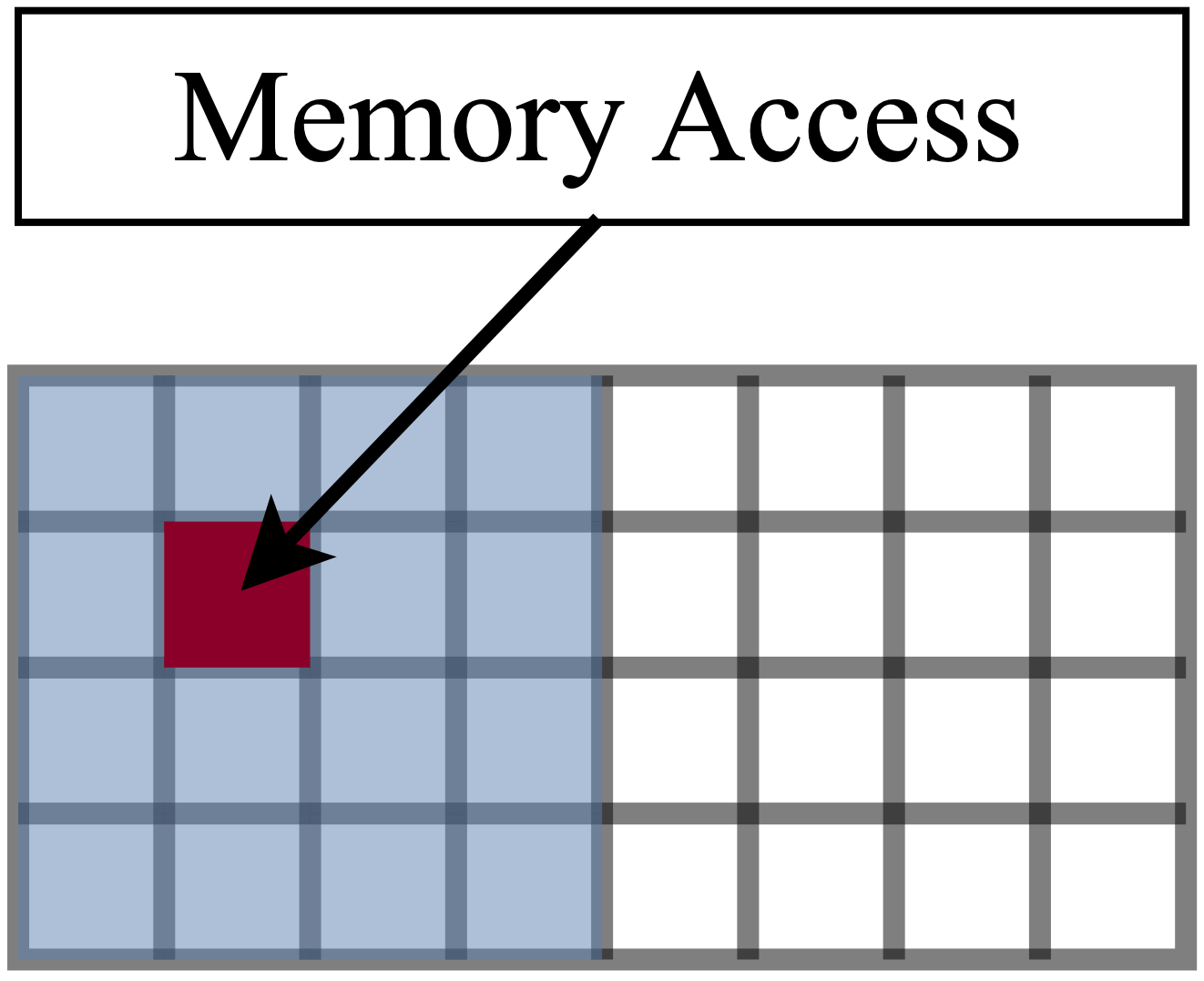
Memory access for a hardware with block size 16: one (red) location access means full 16×× (blue) access.
- **Layer Agnostic Sparsity**: Most existing work targets a single type of operation such as attention ([Child et al. 2019](https://arxiv.org/abs/1904.10509), [Zaheer et al. 2020](https://proceedings.neurips.cc/paper/2020/file/c8512d142a2d849725f31a9a7a361ab9-Paper.pdf)), whereas neural networks often compose different modules (attention, MLP). In many applications the [[Multi Layer Perceptrons]] layers are the main training bottleneck ([Wu et al. 2020](https://openreview.net/forum?id=ByeMPlHKPH)).
Therefore, we are looking for simple static sparsity patterns that are hardware-suitable and widely applicable to most NN layers.
------
#### Sparsity Methods
Sparsity techniques aim to **simplify AI models** by distilling and pruning them to retain only the most impactful elements. This is similar to how the human brain optimizes its functionality by switching off less crucial connections.
Researchers have developed various approaches to incorporate sparsity into AI models:
- [[Pixelated Butterfly]]| [Butterflies are all you need](https://dawn.cs.stanford.edu/2019/06/13/butterfly/)
- [[Pruning]]
- [[Distillation]]
- [[Sparse Transformers]]
- [[Quantization]]
---
#### Sparsity connection to Scaling
It's crucial to understand the balance between model size and computational overhead. Existing analysis from [Kaplan et al.](https://arxiv.org/abs/2001.08361) and the [Chinchilla paper](https://lsems.gravityzone.bitdefender.com/scan/aHR0cHM6Ly9hcnhpdi5vcmcvYWJzLzIyMDMuMTU1NTY=/02FD405A3116396CE1B577442E827B19A9236C28C00F2743B789A2C7AE5A047A?c=1&i=1&docs=1) indicates the existence of a "_critical model size_," the smallest LLM size that can achieve a specific loss level (model success against training examples).
![[Pasted image 20230801122939.png]]
----
![[Pasted image 20230801123224.png]]
As attention mechanisms become increasingly memory-efficient and context windows extend into the million-token scale, the benefits of sparse over dense regimes will become ever more obvious. As we approach the era of _less is more_, it will be worthy to explore, experiment with, and embrace the principles and techniques that sparsity as a paradigm has to offer.
Ref:
1. [Data Centric AI applications](https://github.com/HazyResearch/data-centric-ai#emerging)